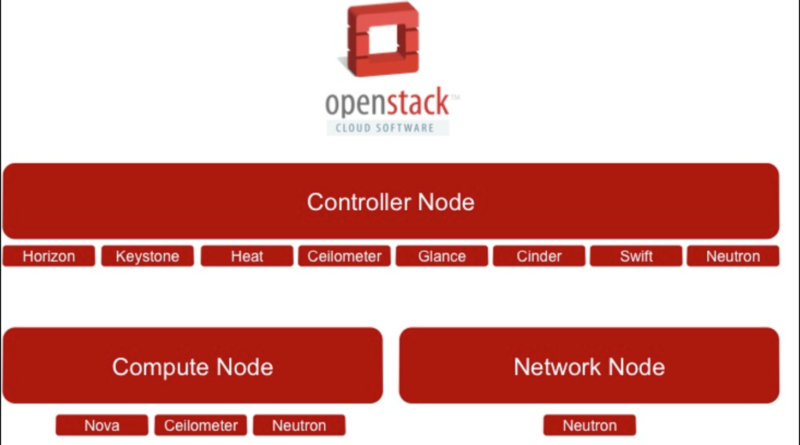
OpenStack Architecture
OpenStack Platform is implemented as a collection of interacting services that control compute, storage, and networking resources. Internally, OpenStack services are composed of several processes. All services have at least one API process, which listens for API requests, preprocesses them and passes them on to other parts of the service. With the exception of the Identity service, the actual work is done by distinct processes. To communicate between the processes it uses an AMQP (Advanced Message Queuing Protocol) message broker. The service’s state stored in a database.
While deploying and configuring OpenStack Cloud we can use several databases (MySQL, MariaDB,SQLite etc.) and message brokers(ActiveMQ, RabbitMQ etc).
OpenStack Glance has a client-server architecture that provides a REST API to the user through which requested task can be performed on the server.
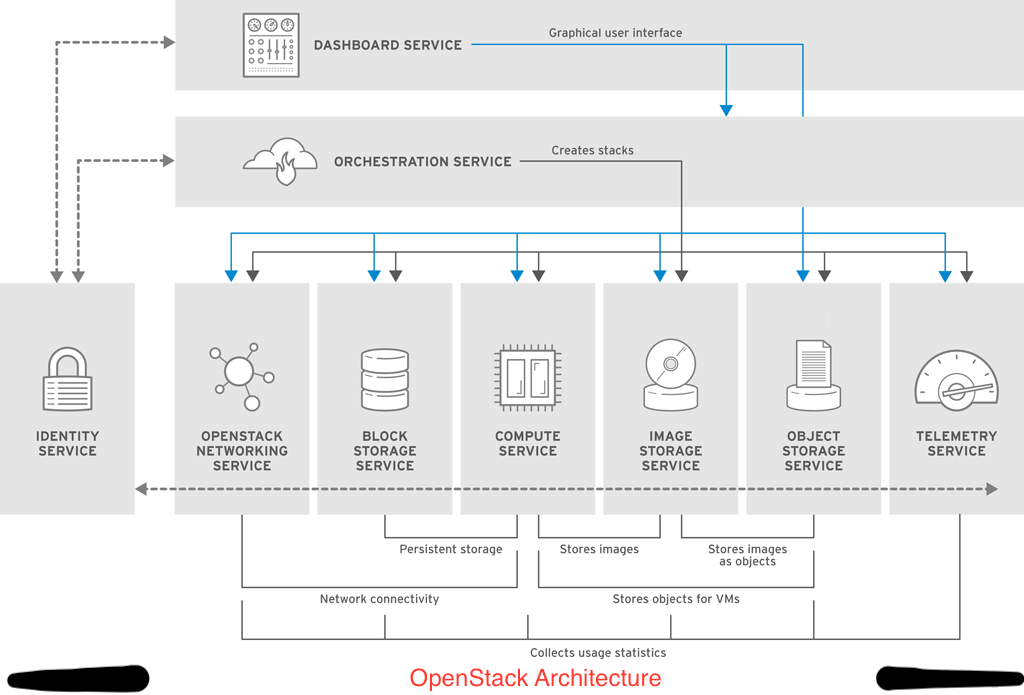
Different OpenStack Services
OpenStack uses many services to manage and control OpenStack components.
Dashboard (horizon)
Dashboard is a browser-based interface which is used for managing OpenStack services, it provides a graphical interface for launching instances, managing networking, and setting access controls.
Identity Service (keystone)
Identity service is used to provide authentication and authorization to all OpenStack services. Identity service provides a central catalog of other services and associated end points. It supports multiple forms of authentication including user name and password, token-based, and Amazon Web Services (AWS) logins. It acts as a single sign-on (SSO) authentication service for users and components. This service is also responsible for creating and managing users, roles, domains and projects.
- Users: The Identity service validated the requests that are made by OpenStack users. It uses tokens to provide user role information to access specific project resources.
- Projects: A project is a group of resources( i.e users, networks, images, volumes etc). Projects helps to isolate and groups identity objects and project resources. Depending upon the requirement a project can be mapped to a customer, account, organization or development environment.
- Domains: A Domain defines administrative boundaries of identity service entities. A domain can have one or more users, groups and projects. In a multi-tenant cloud, multiple identity providers providing authentication and authorization service can be each associated with a separate domain. resources associated with one domain can not be sharable or accessible in other domains.
OpenStack Networking service (neutron)
It is a Software-Defined Networking(SDN) service thats helps to create networks, subnets, routers and floating IP addresses. OpenStack networking ships with multiple plug-ins and agents Cisco virtual and physical switches, Open vSwitch, OVN, and others. Common agents are L3 and DHCP (which provides DHCP IP addresses to instances). OpenStack networking enables projects to create advanced virtual network topologies including entities such as firewalls, load balancers, and virtual private networks (VPNs).
Block Storage service (cinder)
The block storage service manages storage volumes for instances. It can be both ephemeral and persistence block storage for the instances running in the compute service. We can take snapshots for backing up data, either for restoring data or to be used to create new block storage volumes.
Compute service (nova)
The Compute service manages instances, provides instances on demand. It is a distributed service and interacts with the Identity service for authentication, Image service for images, and dashboard as a web-based user interface. It is designed to scale out instances horizontally on standard hardwares, downloading images to launch instances as required. It uses libvirtd, qemu, and kvm for the hypervisor.
Image service (glance)
The Image service acts as a registry for virtual machine images, allowing users to copy server images for immediate storage. These images can be used as templates when setting up new instances.
Object Store service (swift)
The Object Store provides object storage that allows users to store and retrieve files. The Object Store architecture is distributed to allow for horizontal scaling and to provide redundancy as a design to avoid failure or object loss.
One use case for Object Store is that it can act as a storage back end for images. This allows OpenStack to replicate images and snapshots across the Object Store infrastructure. This solution is useful as a backup, because it can store the images and instances on different physical servers.
Telemetry service (originally ceilometer)
The Telemetry service provides user-level usage data, which can be used for customer billing, system monitoring, or alerts. It can collect data from notifications sent by OpenStack services such as Compute usage events, or by polling OpenStack infrastructure resources. Additionally, the service provides a plug-in system that can be used to add new monitoring metrics. The original Telemetry service has evolved to become three interconnected components.
- Alarming service (aodh): Enable the ability to trigger actions based on defined rules against sample or event data collected by Ceilometer.
- Timeseries database service (gnocchi): Storage and indexing of time series data and resources at a large scale. Useful in modern cloud platforms which are not only huge but also are dynamic and potentially multi-tenant. Gnocchi has been designed to handle large amounts of aggregates being stored while being performant, scalable and fault-tolerant. This component is no longer an OpenStack project, having grown to become an open-source project on its own.
- Event, metadata indexing service (panko): Panko is designed to provide a metadata indexing, event storage service which enables users to capture the state information of OpenStack resources at a given time. Its aim is to enable a scalable means of storing both short and long term data for use cases such as auditing and system debugging.
Load Balancing service (octavia)
The Load Balancing service was designed to create a standalone load-balancing component, to replace the original networking server (neutron) LBaaS project which was based on HAproxy. The new service delivers load balancing services managed as virtual machines, containers, or bare metal servers (collectively known as amphorae) which are spun up on demand, providing stronger horizontal scaling.
Orchestration service (heat)
The Orchestration service orchestrates multiple composite cloud applications using the Amazon Web Services (AWS) CloudFormation template format, through both a Representational State Transfer (REST) API and a CloudFormation-compatible Query API.
Additional Supported Services
OpenStack platform supports many additional services, which are discussed below.
Red Hat Ceph Storage (ceph)
Red Hat Ceph Storage integrates with OpenStack services such as compute, block storage, shared file-system, image, identity, and object to give more flexibility storing images and volumes and operating at scale. It is a distributed data object store designed to provide excellent performance, reliability, and scalability.
Shared Filesystems service (manila)
The Shared File Storage service is a secure file share as a service. It uses the NFS and CIFS protocols for sharing file systems. It can be configured to run on a single-node back end or across multiple nodes.
Deployment service (tripleo)
The Deployment service code handles installing, upgrading, and operating OpenStack clouds using OpenStack’s own services as the foundation. It uses Compute, Networking, and Orchestration services, and other orchestration tools, such as Puppet, and Ansible, to automate fleet management, including scaling out and scaling back at data center scale.
Bare Metal Provisioning service (ironic)
The Bare Metal Provisioning service enables the user to provision physical hardware as opposed to virtual machines. It provides several drivers such as IPMI and PXE to cover a wide range of hardware. It also allows vendor-specific drivers to be added.
Big Data Processing Framework service (sahara)
The Big Data Processing Framework service provide users with a simple means to provision a data processing cluster (such as Hadoop, Spark, and Storm) on OpenStack.
Container Deployment service (kolla)
The service provides production-ready containers and deployment tools for operating OpenStack clouds that are scalable, reliable, and upgradable.
Benchmarking service (rally)
The Benchmarking service is a benchmarking tool that automates and unifies multi-node Red Hat OpenStack Platform deployment, cloud verification, benchmarking, and profiling. It can be used as a basic tool for a system that would continuously improve its SLA, performance and stability.
Integration Testing service (tempest)
The Integration Testing service provides a set of integration tests that run against a live OpenStack cloud. The Benchmarking service uses Integration Testing service as its verifier. It has several tests for OpenStack API validation, scenarios, and other specific tests useful in validating an OpenStack deployment.
Messaging service (zaqar)
This is a multi-tenant cloud messaging service designed for sending messages between various components of their applications. It is an efficient messaging engine designed with scalability and security in mind. Other OpenStack components integrate with Zaqar to surface events to end users and to communicate with guest agents that run in the overcloud.
Cloud controller
It is also called as coordinating manager. All machines in the OpenStack cloud communicate with the cloud controller using the REST API. Individual sub-components communicate with the Advanced Message Queuing Protocol (AMQP). OpenStack Platform, there are two options for AMQP: the Apache Qpid messaging daemon (qpidd), and RabbitMQ.
For more information about OpenStack you can go here
You can also read Kubernetes and OpenShift Architecture in my another post Architecture of Kubernetes & OpenShift.
I hope you like this post, if you have any questions? please leave comment below!
Thanks for reading. If you like this post probably you might like my next ones, so please support me by subscribing my blog.