Affinity Propagation (AP Algorithm): Definition, Explanations, Examples
Introduction
Affinity Propagation is a clustering algorithm used in machine learning and data analysis. It is a relatively new algorithm that has gained popularity due to its ability to automatically determine the number of clusters in a dataset. In this blog post, we will explore the definition, explanations, and examples of Affinity Propagation.
Definition
Affinity Propagation is a clustering algorithm that aims to find exemplars, or representative points, in a dataset. Unlike traditional clustering algorithms that require the number of clusters to be specified in advance, Affinity Propagation automatically determines the number of clusters based on the data. It does this by iteratively exchanging messages between data points to find the most representative points.
The core idea behind Affinity Propagation is that each data point can act as an exemplar, and the algorithm seeks to find the best exemplars that represent the entire dataset. The algorithm takes into account both the similarity between data points and their suitability to be exemplars.
Explanation
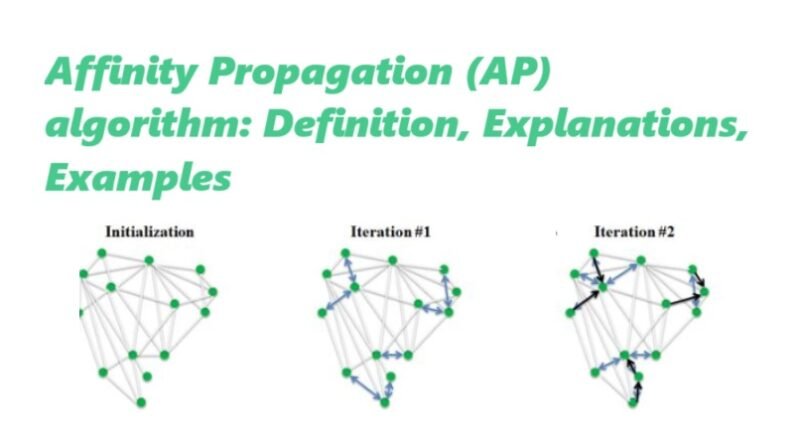
The Affinity Propagation algorithm can be divided into several steps:
- Similarity Matrix: The first step is to calculate the similarity between each pair of data points in the dataset. This similarity can be based on various metrics, such as Euclidean distance or correlation.
- Responsibility: In this step, each data point sends a message to other data points indicating how well-suited it is to be an exemplar. The responsibility value reflects the accumulated evidence for a data point to be an exemplar based on its similarity to other data points.
- Availability: The availability value represents the accumulated evidence for a data point to choose another data point as its exemplar. It is updated based on the responsibility values and the availability values of other data points.
- Exemplars: After several iterations of updating the responsibility and availability values, the algorithm identifies the exemplars. These exemplars are the representative points that best capture the characteristics of the dataset.
- Clustering: Finally, the data points are assigned to the exemplars, forming the clusters.
Examples
Let’s consider an example to illustrate how Affinity Propagation works. Suppose we have a dataset of customer preferences for different products. The goal is to cluster the customers based on their preferences.
First, we calculate the similarity between each pair of customers based on their preferences. Next, we initialize the responsibility and availability values for each customer. Then, we iteratively update these values based on the messages exchanged between the customers.
After several iterations, the algorithm identifies the exemplars, which are the customers that best represent the entire dataset. Finally, the remaining customers are assigned to the exemplars, forming the clusters.
By using Affinity Propagation, we can automatically determine the number of clusters and find the most representative points in the dataset. This can be valuable in various applications, such as customer segmentation, image analysis, and social network analysis.
Conclusion
Affinity Propagation is a powerful clustering algorithm that provides an automatic and flexible approach to finding clusters in a dataset. It eliminates the need to specify the number of clusters in advance and can handle complex data structures. By understanding the definition, explanations, and examples of Affinity Propagation, you can apply this algorithm to various real-world problems and uncover meaningful insights from your data.
Reference: What is AP Algorithm Basics